A regressão linear é um modelo matemático usado para estudar a relação entre duas variáveis - uma contínua e outra contínua ou ordinal - e a partir do qual se tenta prever os valores de uma das variáveis em função da outra.
Já vimos anteriormente que a correlação é usada para medir a 'força' da relação linear entre duas variáveis. A regressão linear é usada para estudar a natureza dessa relação. Ao contrário da correlação, é necessário distinguir qual a variável que se tenta prever (variável dependente) e a variável que prevê (variável independente).
No estudo sobre o consumo de vegetais e taxa de mortalidade por cancro do estômago, a situação mais natural é tentar prever qual a taxa de mortalidade (variável dependente) para um determinado consumo de vegetais (variável independente) e não o contrário.
A definição do papel de cada variável é importante pois o modelo resultante depende dessa escolha ainda que a correlação seja igua nas duas situações. Ou seja, o modelo para prever a mortalidade para o consumo de vegetais é distinto do modelo para prever o consumo de vegetais através da mortalidade.
Graficamente o modelo de regressão linear é apresentado como a recta que melhor aproxima a relação entre a variável dependente e a variável independente. Esta recta já tinha sido usado para se ter ideia da magnitude da correlação (figura 3 e figura 4), mas nada foi dito quanto à sua construção.
y = b0 + b1*x, onde b0 é a ordenada na origem (onde a recta se cruza com o eixo dos Y) e b1 é o declive da recta
No exemplo estudado a equação pode ser traduzida para,
tx mortalidade = b0 + b1 * consumo de vegetais
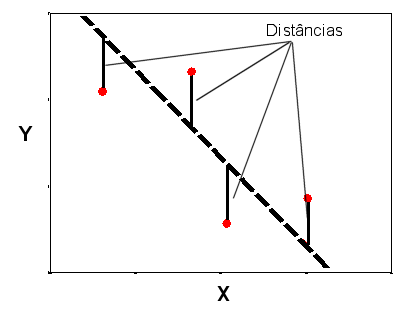
Para definir esta recta, basta então encontrar os coeficientes b0 e b1. Estes valores são calculados de tal maneira que a soma das distâncias indicadas na figura 7 à recta seja a menor possível, ou seja, b0 e b1 são calculados de forma a minimizar a soma das distâncias à recta.
Nota: A dedução das fórmulas para b0 e b1 não está no âmbito deste curso.
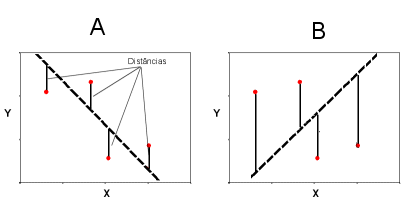
Por exemplo, no gráfico A da figura 8, a soma das distâncias à respectiva recta é inferior à do gráfico B. Assim, a recta do gráfico A é um modelo melhor do que a de B.
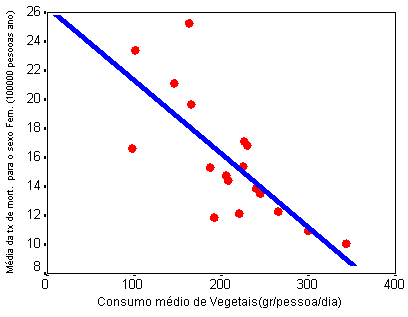
No estudo da mortalidade por cancro do estômago, a recta que melhor prevê a mortalidade feminina por consumo de vegetaisé a da figura 3 e tem equação :
y = 26.33 - 0.05x (figura 9)
Ou,
tx mortalidade feminina = 26.33 - 0.05 * consumo de vegetais
(Como obter os coeficientes da regressão b0 e b1 no SPSS?)
A interpretação dos coeficientes b0=26.33 e b1=0.05 é a seguinte:
b0 - o valor previsto da mortalidade com um consumo nulo de vegetais. Neste caso, a taxa de mortalidade prevista seria 26.33.
b1 - a diminuição (porque o valor de b1 é negativo) prevista da taxa de mortalidade para o aumento de 1 unidade no consumo de vegetais. Neste caso a diminuição prevista da taxa de mortalidade por aumento de 1 unidade no consumo de vegetais é de 0.05.
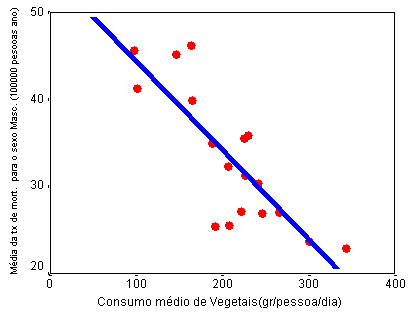
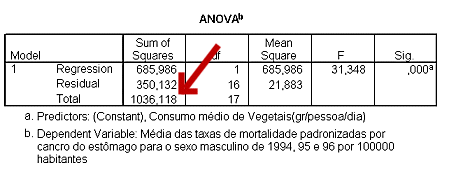
É ainda possível construir uma tabela (normalmente refererida coma a tabela ANOVA) com a indicação da quantidade de variação explicada pelo modelo. No caso da taxa de mortalidade do sexo masculino a variação total é de 1036,118(figura 10).
Nota: O cáculo da variação não está no âmbito deste curso.
Quando se considera o consumo de vegetais, a variação da mortalidade explicada é de 685,986; que aparece na tabela figura 10 com a designação de "Regression" (quantidade de variação explicada pelo modelo). O resíduo é simplesmente a variação que fica por explicar, ou seja a diferença da variação total e variação explicada.
Note que o quociente da variação explicada pela variação total - 685,986/1036,118=0.66 - é a percentagem de variação explicada (o r2) , ou seja, 66%. Como seria de esperar este valor é igual quadrado do coeficiente de correlação (r2) - 0,8142=0,66 - que também indica a percentagem de variação explicada.
Nas últimas colunas da tabela é apresentado um teste de hipótese indicando se a quantidade de variação explicada é significativamente diferente de 0. Neste caso P<0,001, ou seja pode-se considerar que a quantidade de variação explicada pelo modelo é diferente de 0.